半监督学习的思考和安全尝试
Why 为什么在一些安全场景下使用半监督学习?
安全场景-安全数据-安全算法
大多数安全场景对应的安全样本数据都比较少,包括黑样本和白样本,样本数据的缺失直接限制了机器学习技术的应用,这是目前机器学习应用于安全实践中的难题之一。是解决问题还是规避问题呢?这个可以从有监督/无监督/半监督学习的角度来由果推因。如果想采用有监督学习的方法,那么需要大量攻击样本的和正常业务样本的积累,而现实的情况大多数可能是仅有少量攻击样本的积累,这就需要去解决样本数据的问题。针对复杂多变的安全场景,一种解决方式是根据具体业务场景和攻击场景,可以从公开资料寻找数据集,这种数据集一般是成品,方便快捷可以直接利用。另一种解决方式是自己diy,可以从业务数据中打标出一批白样本,可以从各个渠道收集当前业务环境中攻击的payload。这两种解决问题的方式都有问题。基于攻击数据的相似性和业务环境的复杂多样性,可以得出“异常的总是各有相似,正常的总是各不相同”。第一种方式的问题在于,公开数据集的业务环境和我们的业务环境很难高度匹配,这直接导致白样本数据的差异化,导致训练和测试有很大的gap。第二种方式的问题在于选取白样本的成本、代表性、时效性,选取白样本该怎么选比较好,可能的方式是自动化滤出和人工打标。自动化滤出的白样本中可能混杂黑样本造成数据误差,人工打标成本又比较大,同时因为业务环境和业务数据的复杂多变性,可能导致这两种方式都明显存在选取的白样本是否具有代表性的问题。总而言之,在真实业务场景中,白样本其实是比较难选择和持久化的,这正印证了开头的“现实的情况大多数可能是仅有少量攻击样本的积累”。针对固化的安全场景,上面两种方式的劣势将会被减小,但不会消失。所以,在很多复杂多变安全场景中,没有正面解决样本难题或是没有很好的解决样本难题之前,有监督机器学习并不能够很好地解决安全问题。
至于无监督学习,完全不依赖标记数据,同时也没有充分利用已有的标记资源,个人觉得在实际的安全场景中发挥的性能可能还比较局限,难运营。而半监督学习是监督学习和无监督学习的tradeoff,利用已有的标记资源和大量的未标记数据,不增加额外成本,这点优于有监督学习,同时根据“异常的总是各有相似”,使用已标记的黑样本来辅助分类应该能提升模型的性能,这点优于无监督学习。似乎规避样本数据问题的半监督学习更能贴近我们的实际安全场景。
What 半监督学习的安全尝试中我们需要做什么?
安全场景-安全数据-安全算法-数据挖掘-安全算法
举个例子来说,比如要用半监督学习来做Windows恶意软件的预测和识别。从解决方案的视角,首先需要做的是Windows恶意软件的预测和识别。细化来说,安全场景是Windows恶意软件的预测和识别,安全数据是少量黑样本和大量未标记样本的情况。其次从解决方法的视角,需要做的是半监督算法的此场景安全应用。细化来说,需要分析不同半监督学习算法的原理,结合数据挖掘,选择具体的半监督方法。最后需要做的是从数据挖掘视角,结合Windows恶意软件攻击行为模式做数据分析和特征工程来支撑安全算法。
How 半监督学习的安全尝试中我们该怎么做?
上面提到的三个what该怎么做呢,针对第一点解决方案,可以使用Windows机器的软硬件配置数据评估机器被恶意软件感染的概率,使用经过沙箱程度模拟运行的Windows二进制可执行程序的动态行为数据识别Windows恶意软件。针对第二点解决方法,对于少量的正样本和大量的未标记数据,半监督学习中的一个重要分支Pu-Learning(Positive-unlabeled Learning)就是专门解决这种问题的,Pu-Learning又有几种实现方法,比如方式一直接利用标准分类法,将正样本和未标记样本分别看作是positive samples和negative samples,方式二Pu Bagging,利用所有正样本和未标记样本随机组合来创建训练集,再分别将正样本和未标记样本视为positive和negative,最后将分类器应用于不在训练集中的未标记样本。记录并重复此过程。方式三“两步法”,首先识别可以百分百标记为negative的未标记样本子集,再使用正负样本来训练标准分类器并将其应用于剩余的未标记样本。针对第三点数据挖掘,需要分析Windows恶意软件的原理和攻击模式补充安全知识,再结合安全数据进行针对性探索性数据分析,之后从统计学习角度多变量人工挖掘特征(嵌入安全知识指导),自然语言处理角度文本自动化提取特征(嵌入安全知识指导)做数据挖掘。
Do 具体的做法
以解决方法为例介绍一下做法,即半监督学习的安全应用。假设我们已经特征化好了少量的黑样本和大量的未标记样本,开始直接使用。图一是降到2维,上帝视角Unlabeled数据的真实分布,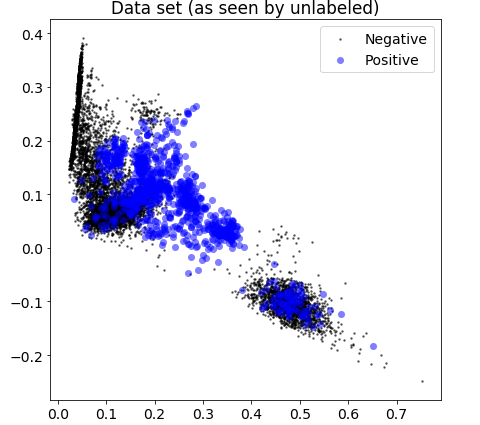
图二是方式一直接利用标准分类方法预测Unlabeled数据的结果,直观看来该方法并不能够很好地逼近上帝视角Unlabeled数据的真实分布,尤其是positive的数据。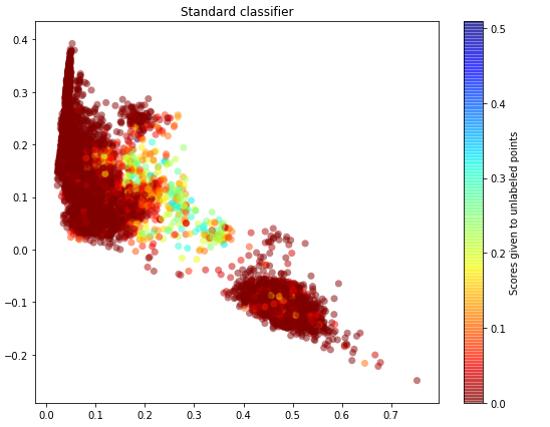
图三是方式二Pu Bagging的结果,可以看出该图较图二似乎更逼近图一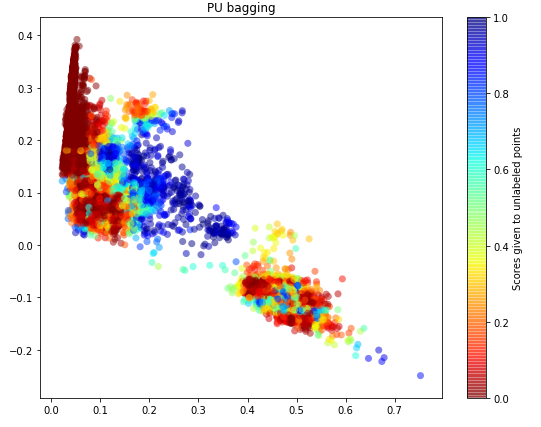
图四是方式三“两步法”step1的结果,可以看出第一轮主要是选出一批足够可信的negative样本,图五是step2的结果,可以看出效果和方式一差不多。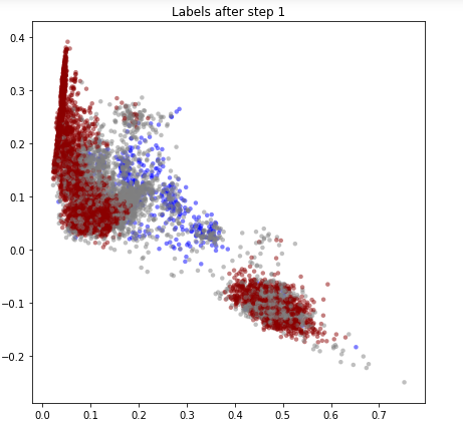
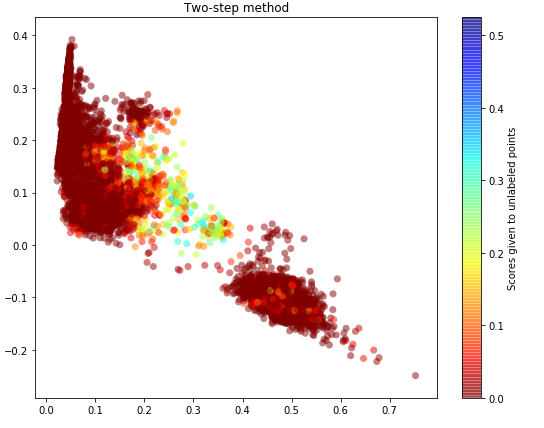
可能这种逼近看起来不够直观,使用输出的概率值加上roc曲线和roc_auc_score评估性能更直观些。data1 std是方式一直接利用标准分类法得出的,data2和data3都是Pu Bagging得出的,data4是两步法得出的。可以得出在此种评价方法下,Pu Bagging>两步法>标准分类法,并且性能还可以。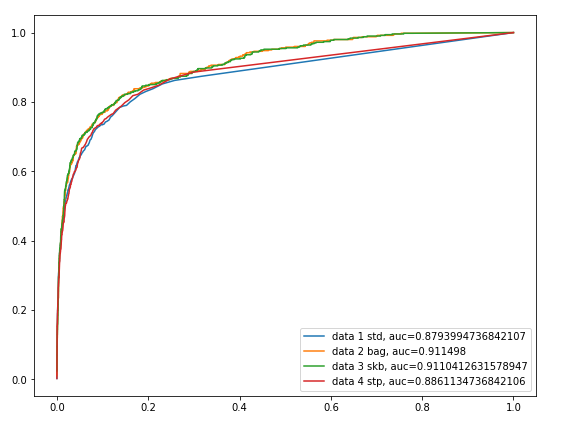
不仅需要在半监督学习算法之间比较,还需要和无监督学习算法比较,如果无监督学习算法不利用已有的标记资源同时性能很好的话,何乐而不为呢。这里选用Isolation Forest来实验,有个问题,由于Isolation Forest的预测概率取值范围是[-1,1],而之前半监督算法的概率取值范围是[0,1],本来是打算将Isolation Forest的概率值除以2再加上0.5,把概率值缩到[0,1]之间,再结合roc和roc_auc_score评价,结果好像有点问题,roc的roc_auc_score才只有0.3+。缓解的一种方法是不输出概率值,直接预测输出标签结果,再使用accuracy_score计算准确率,得出Isolation Forest模型的准确率达到0.88,而半监督学习中标准分类法准确率达到了0.95。证明了在此种评价方法下,至少有一种半监督学习算法优于无监督学习算法。如果标记黑白样本充足的情况下,有监督学习性能大概率是最好的,这里没有衡量也不太好衡量半监督学习和有监督学习差距是多少,想到的一种尝试衡量的方法是保持半监督样本和模型准确率不变,有监督学习要达到同样的准确率需要多少标记资源。
最后,如果完全无安全样本数据积累,同时业务场景复杂多变,样本难获取的话,优先选用无监督学习,如果有一定的安全样本数据积累,同时业务场景复杂多变,优先选用半监督学习,如果业务场景固化,样本容易获取,那么无论有没有样本数据积累,都可以优先选用有监督学习。所以可以得出半监督学习可能更适用于安全场景和复杂业务场景的初期机器学习模型建设。